比较人类产生的语言和 NLP 产生的语言之间的神经活动差异
自然语言处理(Natural Language Processing,NLP)是指使机器能够通过人类日常交流中使用的自然语言与人类进行交互和交流的技术。该技术允许计算机通过自然语言生成来表达给定的意图和想法。
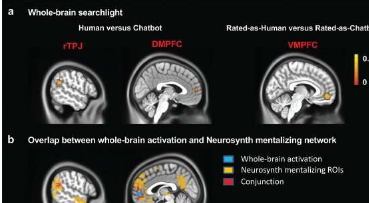
在Advanced Science发表的一项研究中,来自中国科学院 (CAS) 中国科学技术大学 (USTC) 的张晓初教授及其团队证明了隐性神经信息在语言感知和理解中的关键作用:比较神经活动人类产生的语言和 NLP 产生的语言之间的这项研究还为评估自然语言生成的质量提供了有前途的想法。
NLP 研究界长期以来一直在寻求生成与人类语言质量相匹配的语言。尽管该领域取得了巨大进步,但评估 NLP 生成的语言的质量仍然面临重大挑战。语言心理学研究表明,语言包含关于说话者的丰富的社会和心理信息,主要由读者或听众在隐含的层面上处理。因此,在自然语言质量评价标准中加入隐含感知信息是一个很有前途的潜在方向。
在这项研究中,张教授团队收集了聊天机器人谷歌Meena和微软小冰的语料库作为NLP生成语言的代表,并收集了人类语料库作为对照材料。功能磁共振成像 (MRI) 技术用于记录参与者浏览和评估两个语料库时的神经信号。
结果分析发现,当参与者主观判断人类语料库和机器人语料库都像人类时,背内侧前额叶皮层和右侧颞顶叶交界区的激活水平是大脑心智化网络的核心区域, 仍然可以显着区分语料库的来源。来自不同来源和不同判断的语料库引发的神经活动在受试者之间表现出显着的相似性。
研究发现,显着激活的大脑区域与荟萃分析神经综合的心智化网络重叠,表明在区分人类产生的语言和NLP产生的语言时涉及内隐知觉的大脑区域确实是心智化网络。
这些发现表明大脑的内隐感觉神经信号对评价信息比自我报告更敏感。将此类信息纳入评估标准有助于开发 NLP 技术。该研究也为开发新的图灵测试来衡量人工智能水平提供了新的视角。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。









