新颖的计算方法证实微生物多样性比以往任何时候都更加丰富
想象一下,研究人员用手电筒探索一个黑暗的房间,只能清楚地识别出单束光束中的内容。当谈到微生物群落时,科学家历来无法超越光束——更糟糕的是,他们甚至不知道房间有多大。

《自然》杂志上发表的一项新研究强调了微生物的大量功能多样性,通过一种新方法通过观察微生物内部的蛋白质功能来更好地了解微生物群落。这项工作由美国能源部(DOE)联合基因组研究所(JGI)的科学家团队、位于劳伦斯伯克利国家实验室(伯克利实验室)的能源部科学用户设施办公室以及多个其他研究中心的合作者领导世界各地。
该论文的主要作者、现任生物医学科学研究中心亚历山大·弗莱明研究主任的乔治斯·帕夫洛普洛斯(GeorgiosPavlopoulos)说:“迄今为止,我们已经将已知的蛋白质家族数量增加了一倍以上,并确定了许多新颖的结构预测。”“这是通过大规模并行计算对13亿种蛋白质进行的大规模分析。”
在JGI科学家的指导下,该团队开始执行一项任务,揭开隐藏在“黑暗”功能领域的秘密。他们的重点集中在破译蛋白质功能多样性的复杂世界上:新的蛋白质家族和尚未揭晓的微生物中的新功能。
他们利用26,000多个微生物组数据集的集体力量(所有这些数据集均可通过公开的集成微生物基因组和微生物组(IMG/M)数据库访问),成功地制作了新型宏基因组蛋白质家族(NMPF)目录。
该研究的资深作者、JGI微生物组数据科学小组负责人NikosKyrpides表示:“我们现在可以通过与这些蛋白质家族进行比较来分析新数据集,或者进一步分析蛋白质家族以预测新功能。”
揭示功能性“暗物质”
从土壤、胃到深海,无处不在的微生物群落能够在能源循环方面做出许多独特的事情——将生物质转化为乙醇或氢气,或将太阳能转化为氢气。
微生物群落的研究也极其困难。其中的许多微生物无法在实验室环境中培养。由于每个微生物群落都有其独特的微生物参与者组成及其所执行的功能,因此人工复制整个群落是不可能的。
宏基因组测序使研究人员能够通过样本的全基因组测序来研究这些群落的整个基因组成,而无法区分哪个基因属于群落中的每个微生物物种。因此,该过程取决于对现有基因组序列的参考。
其中一些蛋白质被科学家称为“已知的已知蛋白质”——也就是说,它们与具有已知功能的基因相似。其他基因被称为“已知的未知基因”——也就是说,它们与先前已知的分离生物体基因相似,但我们仍然不确定它们的功能。
然而,如果群落中的某个基因与分离株中任何先前已知的基因都不匹配,那么科学家就无法了解其功能或起源。因此,这些基因通常作为无用信息从任何分析中被丢弃。这些代表“未知的未知数”,因为它们与我们已经定义的任何东西都不相似。
Kyrpides说:“到目前为止,我们所知道的蛋白质家族中,有很大一部分——大约30-50%——仍然没有任何已知的功能,但我们知道这些家族。”然而,“近20年的宏基因组数据和宏基因组分析,仍然没有对宏基因组本身的蛋白质家族进行真正的分析。”
最近,其他研究团队利用人工智能的力量来解码蛋白质序列的语言,并获得其可能功能的提示。然而这些努力仅限于已知的蛋白质序列领域。
帕夫洛普洛斯说:“在这一努力中,我们不仅冒险进入了了解功能多样性广阔前景的未知领域,而且还通过应用人工智能方法来阐明它们的作用,从而突破了界限。”“因此,我们积累了广泛的突破性见解,显着扩大了各种蛋白质类别的潜在功能范围,包括那些在生物技术中具有关键应用的蛋白质,例如DNA编辑酶。”
以新方式利用蛋白质家族
近年来,新蛋白质家族的发现开始趋于平稳,这或许表明科学家们已经“捕获”了大部分的多样性,即使它还没有准确地定义它的作用。但那些“未知的未知”可能拥有什么样的多样性呢?
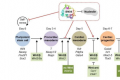
该团队从IMG的80亿个宏基因组基因开始(该研究还参考了JGI地球微生物组基因组(GEM目录)的数据)。然后,他们删除了任何与先前已知基因哪怕有一点点相似性的基因,留下了大约12亿个新基因。
他们带走了剩下的一切,并将他们聚集成家庭。从那时起,他们重点关注拥有至少100名成员的家庭。
Kyrpides解释说:“如果有100个序列,则簇的质量会显着提高,因为很难让来自不同位置或栖息地的100个序列随机排列得很好。”“复制100次几乎是不可能的。”
当团队完成这个阶段时,他们发现这个宏基因组空间(“未知的未知”)内的蛋白质家族多样性远远大于参考基因组的多样性,至少两倍。
“随着我们不断添加更多样本,我们得到了更多的蛋白质家族,”基皮德斯说。“几年后,随着我们继续对更多的宏基因组进行测序,一些目前拥有50名或更多成员的簇也将增长到100名或更多成员。所以,我们说多样性已经翻倍,但实际上它可能会增加是三倍、四倍、五倍或十倍。”
进一步挖掘一系列多样性
虽然团队没有深入研究功能,但他们能够进一步描述这些家族的特征。他们按环境对蛋白质家族进行了划分,发现只有7%的蛋白质家族在所有八个环境类别中是相同的。相反,家庭更喜欢特定的环境——无论是土壤、动物宿主、海洋生态系统等。
“所以,他们一定在为这个栖息地做一些有趣或重要的事情,”帕夫洛普洛斯解释道。“这绝对是科学界现在可以进一步使用的材料。假设有人正在研究土壤环境或人体,他们可能会选取其中一些家族并尝试对它们进行功能表征,因为它们对于该栖息地非常特定。”
分类学分析发现,大多数这些蛋白质家族属于细菌和病毒,尽管有600万个序列逃避了分类。研究人员还尝试通过3D建模来研究基因的功能,并将未知结构与已知结构进行比较——相似的结构意味着相似功能的可能性很高。该团队还鉴定了具有全新结构的蛋白质家族。
执行这种级别的分析的计算能力取决于对国家能源研究科学计算中心的访问,这是伯克利实验室的另一个用户设施。
帕夫洛普洛斯说:“这也是艾丁·布鲁克(AydinBuluç)团队与伯克利实验室应用数学和计算研究部门的功劳。”“他们开发了并行算法来执行‘全面对比’比较和图形聚类,能够在如此高度并行的基础设施中运行。”
这是蛋白质结构首次被用来帮助表征大量的微生物暗物质。这项研究大约花了两年时间才完成,当时仅对约20,000个宏基因组进行了测序。现在,这个数字接近60,000。
“仍有70-80%的已知微生物多样性尚未通过基因组捕获,”Kyrpides说。“因此,就功能多样性而言,这种多样性肯定也蕴藏着许多新的秘密。”
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。